

postgres配置与备份恢复
简介
Postges 是一个关系型数据库管理系统(DBMS),目前流行度、功能性、口碑均击败同定位的 MySQL。“关系型”指用表格形式存储数据,是很符合直觉的存储形式。另一条数据库赛道是非关系型数据库(NoSQL),代表如 Redis、MongoDB 等,在此不作展开
Postgres 提供了丰富的抽象层级,从上到下是:
- Cluster,最顶层的概念,可包含多个 database。不同 cluster 在操作系统上使用独立的端口号、数据目录、配置目录、日志文件、角色管理,可以作为整体启停,备份恢复时整个 cluster 也常作为基本单元。cluster 对应实现了复杂功能、包含多个应用的复合体。一般来说,默认的 cluster
main已经足够使用 - Database 是对外暴露的接口,作为一个整体提供数据。一般 database 对应一个应用
- Schema 是 table、view 等的逻辑分组,默认的 schema 为
public。例如应用的订单模块、用户模块可使用不同的 schema - Table 直接存储数据,列称为 field,行称为 record。table 需要有 primary key 列,这一列必须每个 record 各不相同
此外,从 table 查找的数据可保存为 view,方便下次使用;index 可以加速特定 field 的查询
好了,你已经掌握大多数核心概念,开始上手吧!
安装
本文使用 Windows 的 Linux 子系统(WSL2),Linux 发行版为 Ubuntu,postgres 版本为 16
参考官方文档,首先更新APT存储库,以保证能找到较新的版本,然后安装
sudo apt install -y postgresql-common
sudo /usr/share/postgresql-common/pgdg/apt.postgresql.org.sh
sudo apt update
sudo apt install postgresql-16
这时,一个名为 postgres 的系统用户已经自动被创建了,是 postgres 的默认超级管理员。可 cat /etc/passwd 查看
postgres:x:108:118:PostgreSQL administrator,,,:/var/lib/postgresql:/bin/bash
为什么不直接用 root 做 postgres 的超级管理员?新建一个用户,有授予最小权限、方便审计追踪、便于系统维护等多重优势
初始的数据库文件在 /var/lib/postgresql/16,配置文件在 /etc/postgresql/16,当前只有默认的 cluster main
使用
服务管理
Postgres 一旦安装,就会作为服务在后台启动。你可以通过多种方式连接该服务,例如使用默认的命令行工具 psql,使用可视化的工具如 navicat,直接通过链接接入应用,甚至通过编程接口访问数据库
首先,我们检查服务是否运行正常
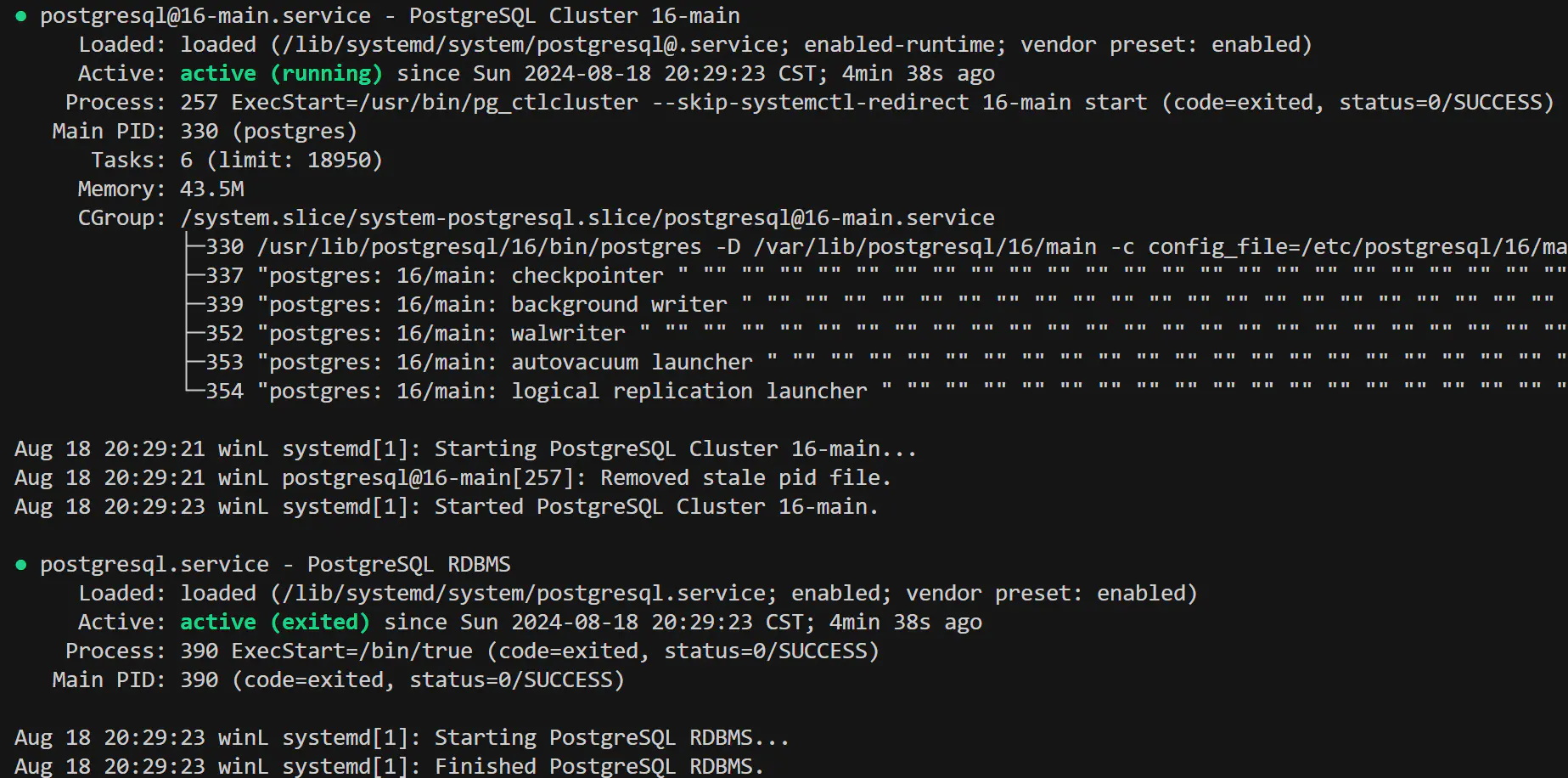
sudo systemctl status postgresql*
你将看到类似这样的输出,Cluster 16-main 代表已启动的 main cluster,RDBMS 代表管理服务。至于为什么有个扎眼的 active (exited), 这里有详细解释
如果运行不正常,可查看日志。日志文件名格式为 postgresql-16-<cluster>.log
sudo tail -n 50 /var/log/postgresql/postgresql-16-main.log
只有在 cluster 正常运行时,数据库才可以被连接。使用以下命令可以管理 postgres 服务的启动、重启、停止
sudo systemctl start postgresql
sudo systemctl restart postgresql
sudo systemctl stop postgresql
为了便于演示,我们创建一个名为 demo 的 postgres cluster
sudo -u postgres pg_createcluster 16 demo --start
pg_lsclusters
如前所述,你会看到 cluster demo 使用新端口 5433

Psql CMD
系统切换到 postgres 管理员用户,调用 psql 进入 postgres 命令行
[william@winL pg]$sudo -i -u postgres
postgres@winL:~$ psql -p 5433
postgres=#
使用 \l 列出 database,\du 列出 roles。可以看到有名为 postgres, template0, template1 三个自带的数据库,一般情况下不要修改它们。还有一个名为 postgres 的 role,属性为超级用户。请注意区分操作系统层面的 system user 和数据库管理系统层面的 role
postgres=# \l
List of databases
Name | Owner | Encoding |
-----------+----------+----------+
postgres | postgres | UTF8 |
template0 | postgres | UTF8 |
| | |
template1 | postgres | UTF8 |
| | |
(3 rows)
postgres=# \du
List of roles
Role name | Attributes
-----------+------------------------------------------------------------
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS
如无必要,不应使用超级管理员访问数据库。我们先创建新 role william,授予其创建 database 的权限,再中断连接、切回到 Linux 系统的同名普通用户
postgres=# CREATE ROLE william CREATEDB LOGIN PASSWORD '000000';
CREATE ROLE
postgres=# \q
postgres@winL:~$ exit
logout
使用 william 连接 demo cluster 下的 postgres database,新建名为 mydb 的 database,并创建名为 info 的 table
[william@winL pg]$psql -d postgres -p 5433
psql (16.4 (Ubuntu 16.4-1.pgdg22.04+1))
Type "help" for help.
postgres=> CREATE DATABASE mydb;
CREATE DATABASE
postgres=> \c mydb
You are now connected to database "mydb" as user "william".
mydb=> CREATE TABLE info();
CREATE TABLE
\dn 列出 shema,\dt 列出 table
mydb=> \dn
List of schemas
Name | Owner
--------+----------
public | postgres
(1 row)
mydb=> \dt
List of relations
Schema | Name | Type | Owner
--------+------+-------+---------
public | info | table | william
(1 row)
你可能注意到了,psql 的语法惯例是,带 \ 的命令小写,保留关键字如 CREATE 大写,database、role、table name 都全小写
如果你想在文件系统中定位 database,需要先确定 oid
mydb=> SELECT oid FROM pg_database WHERE datname = 'mydb';
oid
-------
16389
然后在 /var/lib/postgresql/16/demo/base/16389 即可找到。注意,虽然在 postgres 内部, mydb 由 role william 创建、归属权也是 role william,但在 Linux 操作系统层面,数据库文件的归属者仍是系统用户 postgres
如果你使用 postgres 系统用户,但希望通过其他用户连接 postgres,可能会遇到 Peer authentication 报错
postgres@winL:~$ psql -U william -p 5433
psql: error: connection to server on socket "/var/run/postgresql/.s.PGSQL.5433" failed: FATAL: Peer authentication failed for user "william"
这是因为默认下,postgres 对本地(local)连接只允许 peer 认证,也就是 system user 与 postgres role 同名下的免密码登录
更改默认行为需要在 /etc/postgresql/16/demo/pg_hba.conf,将 METHOD 由 peer 改为 scram-sha-256,即密码验证
# TYPE DATABASE USER ADDRESS METHOD
# "local" is for Unix domain socket connections only
local all all peer
但建议不要更改。这可以简化本地开发、减少密码泄露风险,而且不影响非本地的密码访问
Navicat
打开 navicat,新建连接。Connection Name 随便写,本地的 host 是 localhost,cluster demo 的端口(port)是 5433。登录 postgres role 可以创建 role、新 database,在开发测试时比较方便
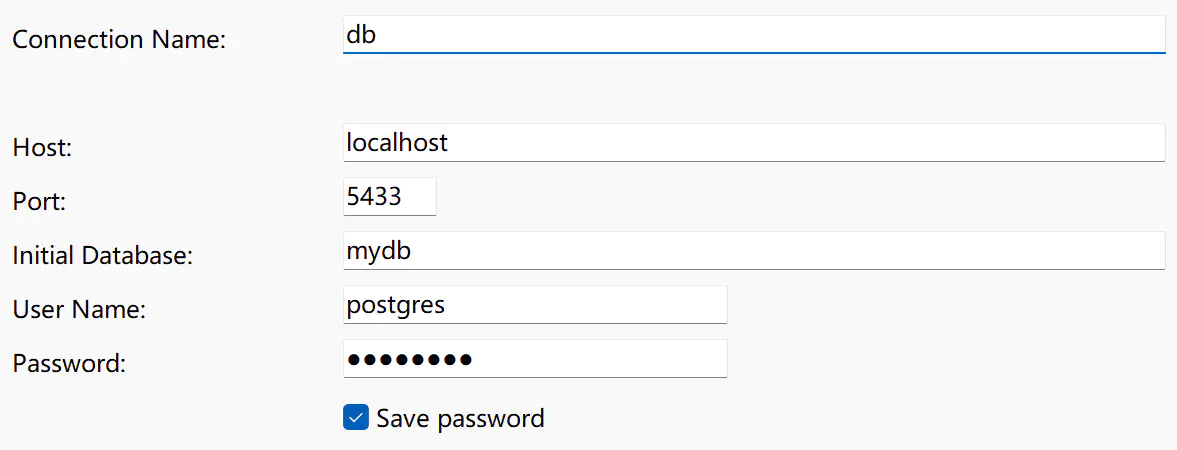
但你还记得吗,role postgres 之前都是 peer 登录,还没设置密码呢
[william@winL ~]$sudo -i -u postgres
postgres@winL:~$ psql -p 5433
postgres=# ALTER ROLE postgres WITH PASSWORD 'your_password';
设好后连接,就能可视化地查看、编辑 table
在特定 table 上右键,选择 design table,可以编辑 table 的 field;左下角的 + 可以新增 record
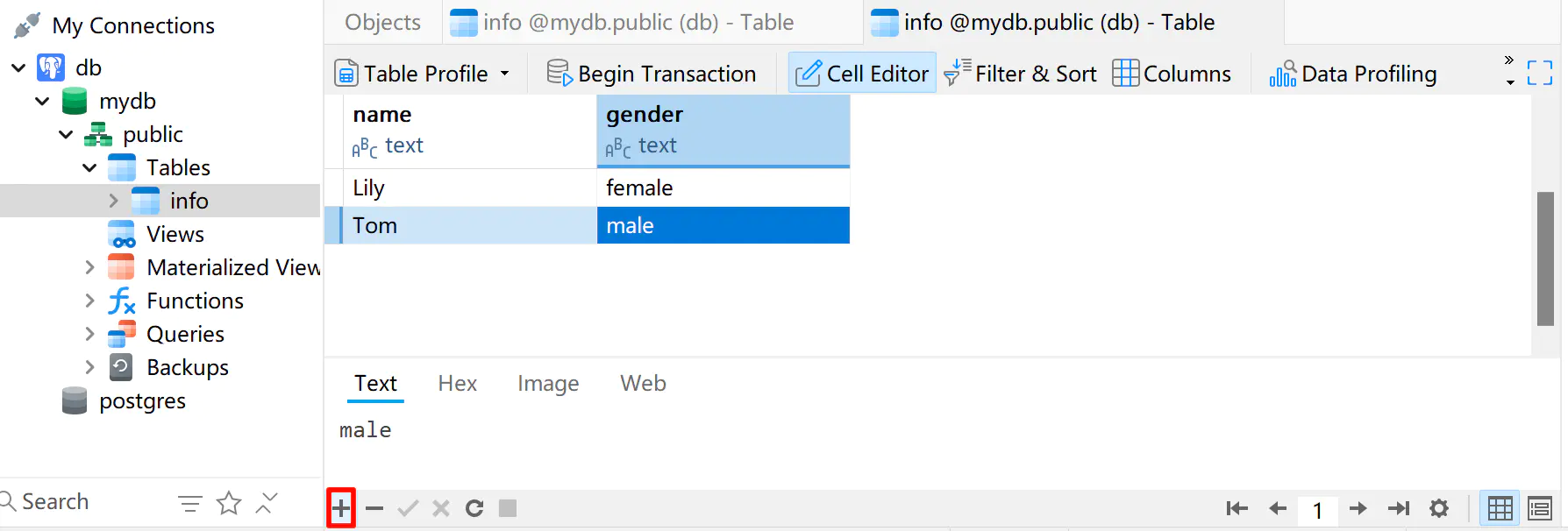
这时在 psql 中,也可以看到新增的记录
mydb=> SELECT * FROM info;
name | gender
------+--------
Lily | female
Tom | male
(2 rows)
接入应用
在这里,我们用 docker-compose 搭建两个应用,连接本地的 postgres 保存数据,看看真实场景下数据库与应用是如何协作的。本节假定读者能够使用 docker 和 docker-compose
在 navicat 创建 role halo,为了演示密码就设为简单的 666666
在 navicat 创建 database halo,并将归属权分配给 role halo
同理创建 role miniflux 和 database miniflux
新建 docker-compose.yml,为简便起见使用 host 网络模式。指定数据库连接时,格式为 postgres://miniflux:666666@localhost:5433/miniflux?sslmode=disable,即 role:password@host:port/database?params
version: "3.4"
services:
halo:
image: halohub/halo:2.13
network_mode: host
command:
- --spring.r2dbc.url=r2dbc:pool:postgresql://halo:666666@localhost:5433/halo
- --spring.sql.init.platform=postgresql
- --server.port=9000
miniflux:
image: miniflux/miniflux:latest
network_mode: host
environment:
- DATABASE_URL=postgres://miniflux:666666@localhost:5433/miniflux?sslmode=disable
- PORT=9100
- RUN_MIGRATIONS=1
- CREATE_ADMIN=1
- ADMIN_USERNAME=rss
- ADMIN_PASSWORD=123456
拉取镜像、创建容器,等待搭建完成
sudo docker-compose up
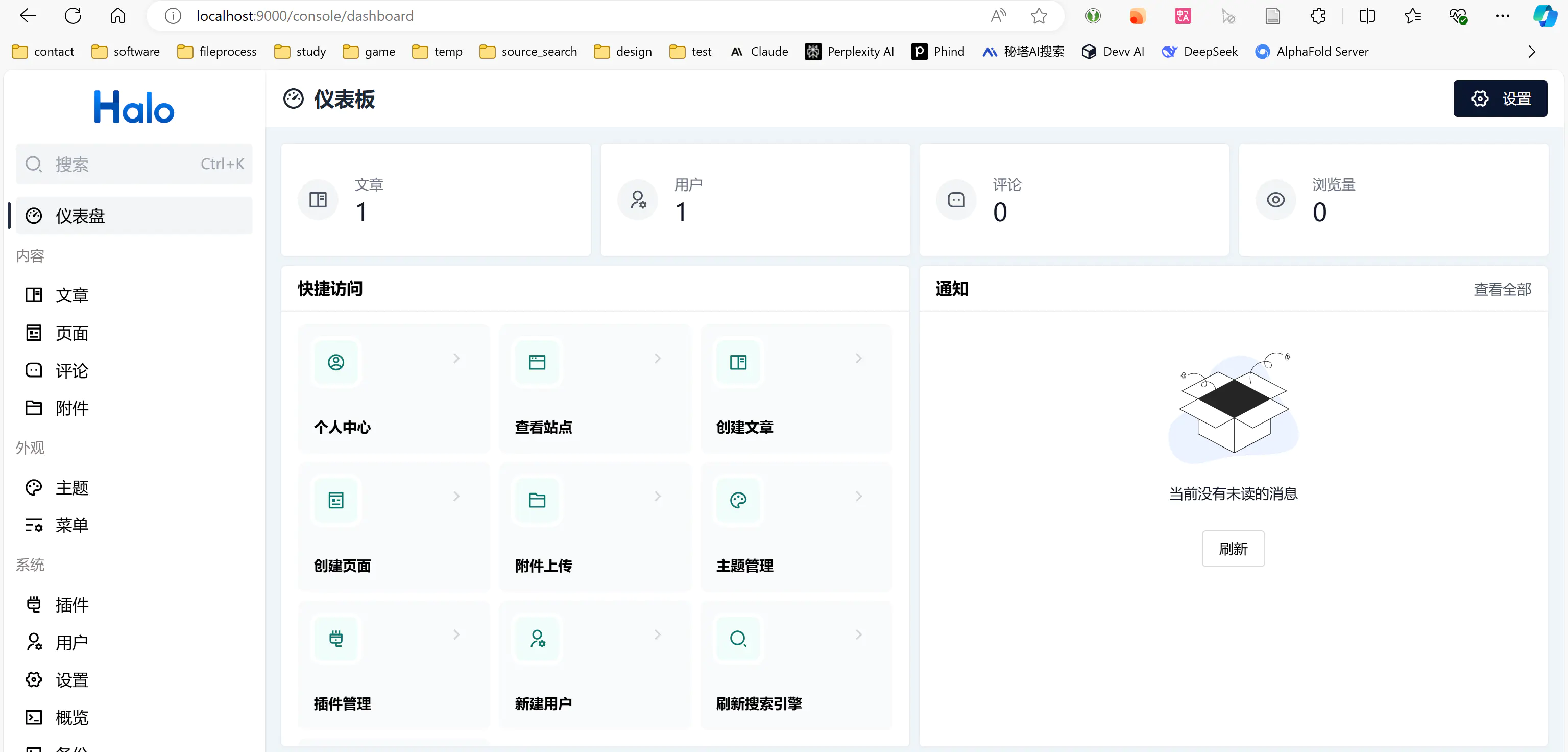
halo 是个博客平台,浏览器访问 http://localhost:9000,就可以开始写作博客了
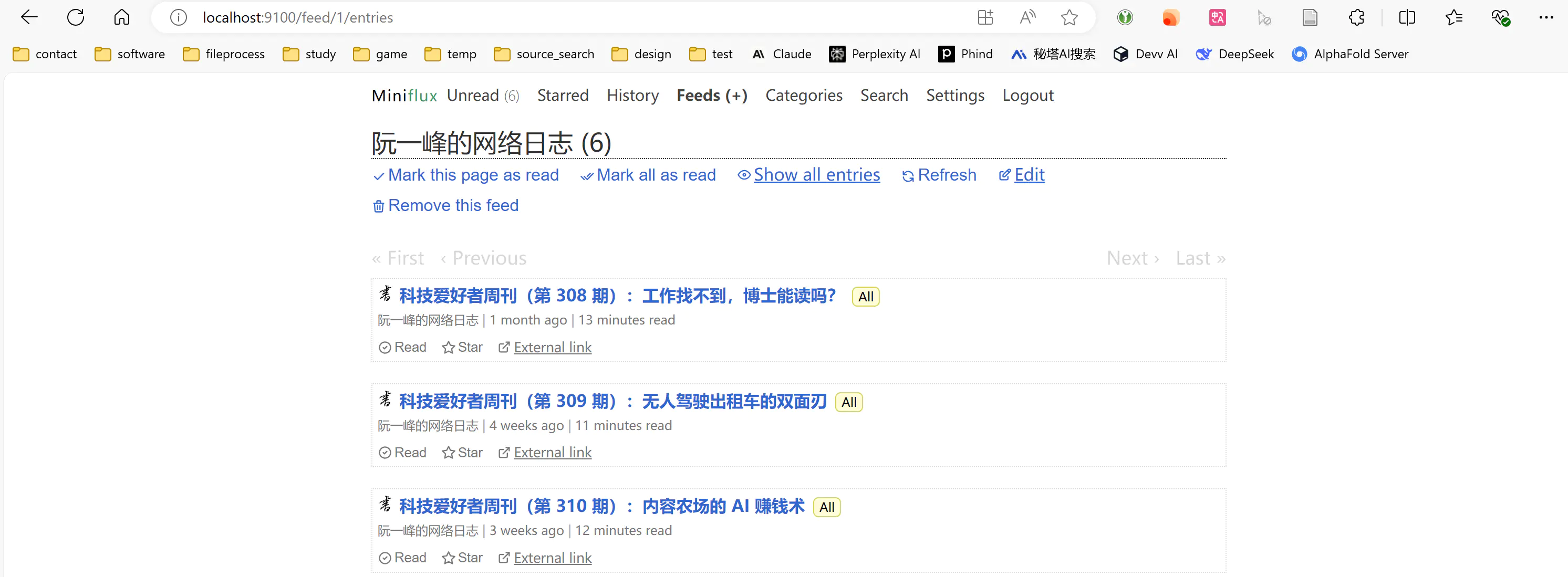
miniflux 是个 RSS 阅读器,浏览器访问 http://localhost:9100,使用账号 rss 和密码 123456 登录,就可以在菜单 Feeds (+) 处订阅 RSS 源。例如 https://feeds.feedburner.com/ruanyifeng,订阅阮一峰的《科技爱好者周刊》
这时,我们回过头看两个应用的数据库架构
halo 的数据库中只有一张 table extension,表中每条 record 都是一个 blob 对象,内部保存的应该是 json,相当于把关系型数据库当非关系型使用,非常简单粗暴。
miniflux 的数据库显然经过更多的设计,有多个不同功能的 table,其中 entries 存储了所有的阅读条目
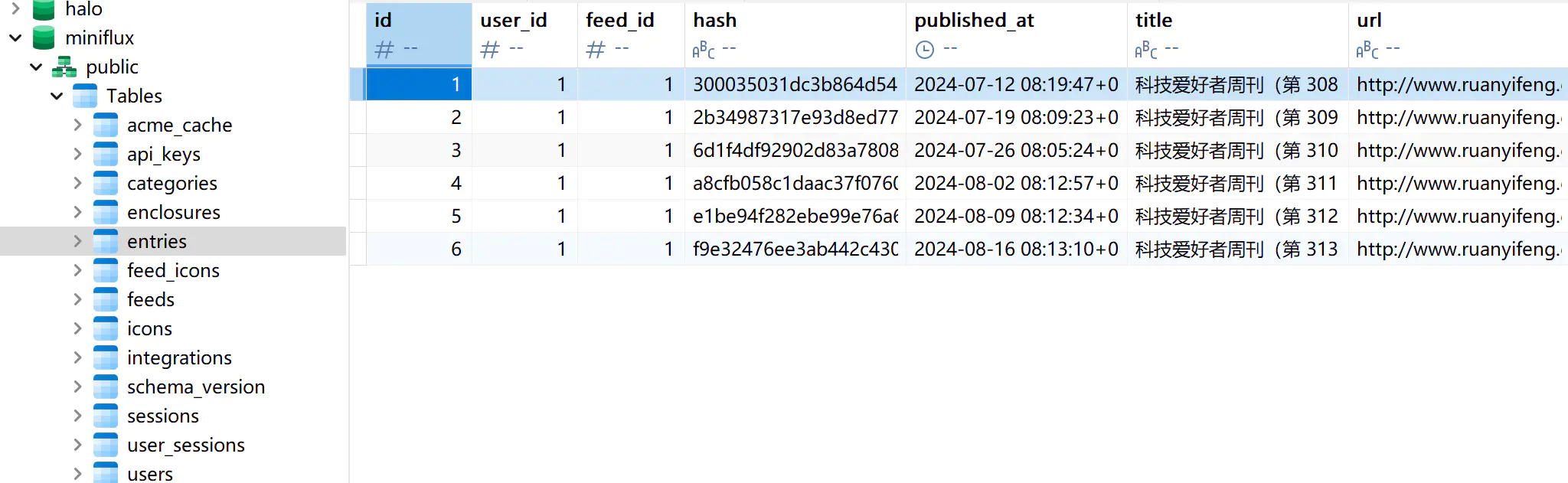
可以看到,虽然有很多所谓数据库设计的“最佳实践”,但在实际生产中还是有很多的自由度
备份恢复
准备
我们对备份最朴素的理解是,第一次创建全量备份,之后每次创建增量备份,即只存储上一次备份以来新增的数据。需要恢复时,将全量备份和历次增量备份结合,整合最新备份用于恢复
在 postgres 中,除了以上基本逻辑外,Write-Ahead Logging(WAL)日志文件记录了数据库的每一次操作,为我们提供了恢复到任意时间点(Point-in-Time Recovery, PITR)的可能
既然有了 WAL,增量备份不就没必要了吗?实际两者互为补充。增量备份粒度不够,但节省空间、恢复速度快
pgBackRest 是专为 postgres 设计的第三方备份软件,相比于 postgre 自带的 pg_dump,pg_basebackup 命令,在压缩、并行、远程备份、自动化等方面做了大量优化
安装 pgbackrest,创建日志、配置目录、备份目录,将权限都赋予系统用户 postgres
sudo apt install pgbackrest
sudo mkdir -m 755 /var/log/pgbackrest
sudo mkdir /etc/pgbackrest /var/lib/pgbackrest
sudo chown postgres:postgres /var/log/pgbackrest /etc/pgbackrest /var/lib/pgbackrest
WAL 文件默认在 /var/lib/postgresql/16/demo/pg_wal 目录,既然目的是备份,我们应默认所有 postgres 相关目录都可能被清空,需要额外的安全位置保存 WAL
可在 /etc/postgresql/16/demo/postgresql.conf 配置保存 WAL 的命令,重启 postgres 应用配置
archive_command = 'pgbackrest --stanza=demo archive-push %p'
archive_mode = on
max_wal_senders = 3
wal_level = replica
其中,%p 代表 postgres 归档的 WAL 文件, pgbackrest archive-push 命令将 WAL压缩复制到 pgbackres 的相应目录。--stanza=demo 的含义下文详解
配置
切换到 postgres 用户
sudo su postgres
在 /etc/pgbackrest/pgbackrest.conf 中写入配置,在备份和恢复时,这些配置都会被读取
[demo]
pg1-path=/var/lib/postgresql/16/demo
pg1-port=5433
[global]
repo1-cipher-pass=zWaf6XtpjIVZC5444yXB+cgFDFl7MxGlgkZSaoPvTGirhPygu4jOKOXf9LO4vjfO
repo1-cipher-type=aes-256-cbc
repo1-path=/var/lib/pgbackrest
repo1-retention-full=2
[global:archive-push]
compress-level=3
每个 postgres cluster 都可单独或组合配置,这在 pgbackrest 中称为 stanza。 [demo] 开启了一个 stanza,我们希望它对应 postgres 的 cluster demo,pg1-path,pg1-port 指定数据路径、端口
[global] 部分的内容对所有 stanza 生效
repo1-cipher-pass是个密码,指定后会加密备份文件。实际生产中,可通过将配置文件设为仅postgres用户可读、从环境变量读取等提高安全性repo1-path指定了备份的保存路径repo1-retention-full指定全量备份最多保留的个数,旧的全量备份会被自动删除
然后运行初始化命令
pgbackrest stanza-create --stanza demo
如果遇到问题可调出日志
pgbackrest --log-level-console=debug check
执行
开始备份,首次执行全量备份,之后默认增量备份
pgbackrest --stanza=demo --log-level-console=info backup
调用 pgbackrest info,即可看到备份信息
stanza: demo
status: ok
cipher: aes-256-cbc
db (current)
wal archive min/max (16): 000000010000000000000002/000000010000000000000004
full backup: 20240822-121032F
timestamp start/stop: 2024-08-22 12:10:32+08 / 2024-08-22 12:10:37+08
wal start/stop: 000000010000000000000004 / 000000010000000000000004
database size: 45.2MB, database backup size: 45.2MB
repo1: backup set size: 6MB, backup size: 6MB
在新主机从头恢复,需要 stanza-create 建好 stanza,并将备份文件放置在对应的路径。恢复之前要停掉 postgres 服务。
pgbackrest --stanza=demo --log-level-console=detail restore
在同一台主机上差异恢复,使用 --delta 选项。如果两个备份间没有任何事务,恢复会失败。
pgbackrest --stanza=demo --log-level-console=detail --delta restore
还可利用 WAL 文件,恢复到特定的时间点
pgbackrest --stanza=demo --delta \
--type=time --target="2024-08-22 12:40:00+08" \
--target-action=promote \
--log-level-console=detail restore
如果你需要恢复到历史时间,确保对 timeline 有所了解。简单来说,恢复会创建新的 timeline,可在 WAL 的前 8 个数字确认目前的 timeline。如果恢复时 timeline 没有对应,将导致 cluster 无法启动
恢复到最新数据时,postgres 永远会切换到最新的 timeline,不需多加考虑;但恢复到历史时间后,将会存在多条 timeline 的重合。可在 /etc/postgresql/16/demo/postgresql.conf 指定恢复的 timeline
云备份
Pgbackrest 支持通过 S3 协议备份,这意味着你可以备份到亚马逊、腾讯、阿里、华为、七牛等任意云厂商,甚至自建的 S3 服务器
实现方式也很简单,修改配置即可
[demo]
pg1-path=/var/lib/postgresql/16/demo
pg1-port=5433
[global]
repo1-type=s3
repo1-s3-key=your_accessKey
repo1-s3-key-secret=your_secretKey
repo1-s3-endpoint=s3.cn-south-1.qiniucs.com
repo1-s3-region=cn-south-1
repo1-s3-bucket=will-dbs
repo1-path=/demo
repo1-retention-full=3
start-fast=y
delta=y
compress-type=zst
compress-level=6
log-level-console=info
log-level-file=debug
当然,你也能本地、S3 同时备份,续写 repo2 就行
周期备份
只需使用 postgres 用户, crontab -e 打开计划表,添加计划(例如每周备份)
@weekly pgbackrest --stanza=demo backup
保存即可
结语
以上,我们探索了数据库如何配置、使用、备份恢复,现在你应该可以管理好自用的数据库,至少不担心丢数据了
如果你需要一个生产环境下极其强大的数据库及配套基础设施,可以考虑 Pigsty
最后,如果你想删除用于演示的 cluster demo
sudo pg_dropcluster 16 demo